To answer this question, I downloaded the DBLP database and used the DOI publisher prefix of each publication to determine its publisher. I grouped the 3.4 million entries by publisher and joined the numeric prefixes with the publisher names available in the list of Crossref members. Based on these data, here is a pie chart of the major publishers of computer science research papers.
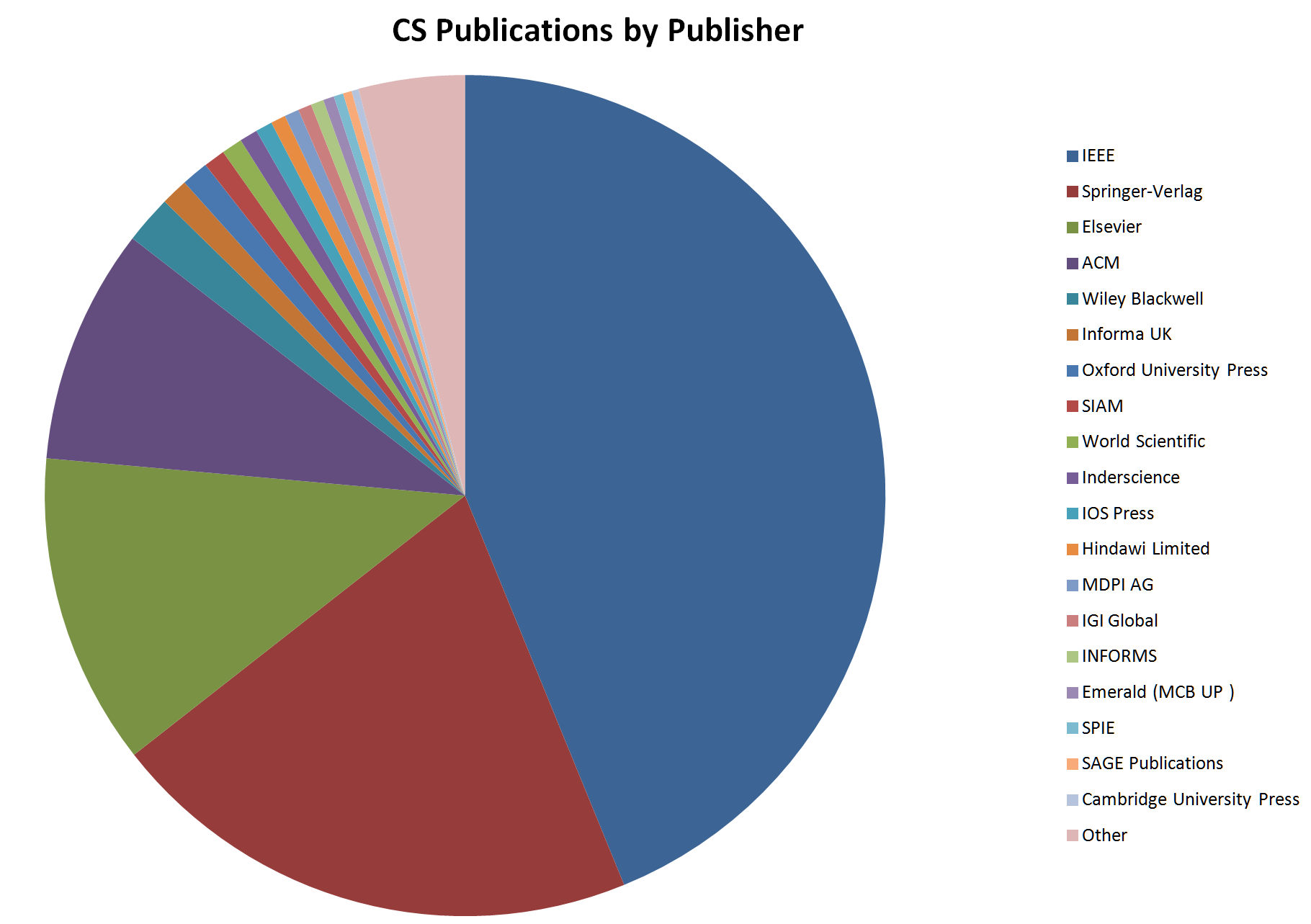 The chart lists the top-20 publishers from the about 150
found in the DBLP database.
The IEEE leads with 44% of the total.
Then comes Springer with 21%, Elsevier with 12%, and ACM with 9%.
All the rest publish fewer than 2% of the papers.
The accuracy of this information obviously depends a lot
on the extent of DBLP’s coverage and also
on the covered venues selection correctness.
Some publishers use multiple prefixes,
because they have acquired others in the past.
I have merged the most important cases.
The chart lists the top-20 publishers from the about 150
found in the DBLP database.
The IEEE leads with 44% of the total.
Then comes Springer with 21%, Elsevier with 12%, and ACM with 9%.
All the rest publish fewer than 2% of the papers.
The accuracy of this information obviously depends a lot
on the extent of DBLP’s coverage and also
on the covered venues selection correctness.
Some publishers use multiple prefixes,
because they have acquired others in the past.
I have merged the most important cases.
Technical Details
I created the list by orchestrating a few Unix command pipelines with the following Makefile.
# Ensure all commands use the same collating order
export LC_ALL=C
# Final result: number of papers by each publisher
cspublisher.txt: csworks.txt publisher.txt
join -t' ' publisher.txt csworks.txt | \
sort -t' ' -k3rn | \
awk -F' ' '{print $$3 "\t" $$2}' >$@
# List of publisher prefixes
publisher.txt: 51depositor.html
sed -n 's/<td><A href="javascript:fred([^)]*)">\([^<]*\).*prefix=\([^"]*\).*/\2\t\1/p' $? | \
sort >$@
# Obtain Crossref members
51depositor.html:
wget 'https://www.crossref.org/06members/51depositor.html'
# Number of works per publisher DOI prefix
csworks.txt: dblp.xml
sed -n 's/<ee>http:\/\/[^/]*\/\([^/]*\).*/\1/p' $? | \
sort | \
uniq -c | \
awk 'BEGIN{OFS="\t"} {print $$2, $$1}' | \
sort >$@
# Obtain ucompressed version of DBLP
dblp.xml:
curl http://dblp.uni-trier.de/xml/dblp.xml.gz | gzip -dc >$@Running make on this file, will execute the following commands.
# Obtain DBLP
curl http://dblp.uni-trier.de/xml/dblp.xml.gz | gzip -dc >dblp.xml
# Print publisher prefixes
sed -n 's/<ee>http:\/\/[^/]*\/\([^/]*\).*/\1/p' dblp.xml |
# Sort them
sort |
# Count them
uniq -c |
# Generate list as prefix, tab, number of publications
awk 'BEGIN{OFS="\t"} {print $2, $1}' |
# Order by publisher prefix
sort >csworks.txt
# Obtain Crossref members as an HTML file
wget 'https://www.crossref.org/06members/51depositor.html'
# Extract the prefix and name of each publisher from the HTML
sed -n 's/<td><A href="javascript:fred([^)]*)">\([^<]*\).*prefix=\([^"]*\).*/\2\t\1/p' 51depositor.html |
# Order by publisher prefix
sort >publisher.txt
# Join publisher number of publications with publisher names
join -t' ' publisher.txt csworks.txt |
sort -t' ' -k3rn |
awk -F' ' '{print $3 "\t" $2}' >cspublisher.txt


Why I Choose Email Over Messaging (2025-09-26)
Is it legal to use copyrighted works to train LLMs? (2025-06-26)
I'm removing the BSD advertising clause (2025-05-20)
The perils of GenAI student submissions (2025-04-11)
Unix make vs Apache Airflow (2024-10-15)
How (and how not) to present related work (2024-08-05)
An exception handling revelation (2024-02-05)
Extending the life of TomTom wearables (2023-09-01)
How AGI can conquer the world and what to do about it (2023-04-13)
Last modified: Friday, September 15, 2017 9:54 pm
Unless otherwise expressly stated, all original material on this page created by Diomidis Spinellis is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.