|
http://www.spinellis.gr/pubs/jrnl/2010-SCP-CScout/html/cscout.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
| CScout | Xrefactory | Proteus | CDT | Refactor! | |
| Number of supported refactorings | 4 | 11 | ∞ | 5 | 150 |
| Handle C namespaces | √ | √ | √ | √ | √ |
| Rename preprocessor identifiers | √ | √ | × | √ | √ |
| Handle scopes introduced by the C preprocessor | √ | √ | × | × | × |
| Handle identifiers created by the C preprocessor | √ | × | × | × | × |
| C++ support | × | √ | √ | √ | √ |
| Yacc support | √ | × | × | × | × |
| User environment | Web | Emacs | - | Eclipse | Visual Studio |
| Reference | [59] | [60] | [42] | [9] |
| Pragma | Action |
| echo string | Display the string on CScout's standard output when the directive is processed. |
| ro_prefix string | Add string to the list of filename prefixes that mark read-only files. This is a global setting used for bifurcating the source code into the system's (read-only) files and the application's (writable) files. |
| project string | Set the name of the current project (linkage unit) to string. All identifiers and files processed from then on will be set to belong to the given project. |
| block_enter | Enter a nested scope block. Two blocks are supported, the first block_enter will enter the project scope (linkage unit); the second encountered nested block_enter will enter the file scope (compilation unit). |
| block_exit | Exit a nested scope block. The number of block_enter pragmasshould match the number of block_exit pragmas and there should never be more than two block_enter pragmas in effect. |
| process string | Analyze (CScout's equivalent to compiling) the C source file named string. |
| pushd string | Set the current directory to string, saving the previous current directory in a stack. From that point onward, all relative file accesses will search the specified file from the given directory. |
| popd | Restore the current directory to the one in effect before a previously pushed directory. The number of pushd pragmas should match the number of popd pragmas. |
| includepath string | Add string to the list of directories used for searching included files (the include path). |
| clear_include | Clear the include path, allowing the specification of a new one from scrarch. |
| clear_defines | Clear all defined macros allowing the specification of new ones from scrarch. Should normally be executed before processing a new file. Note that macros can be defined in the processing script using the normal #define C preprocessor directive. |
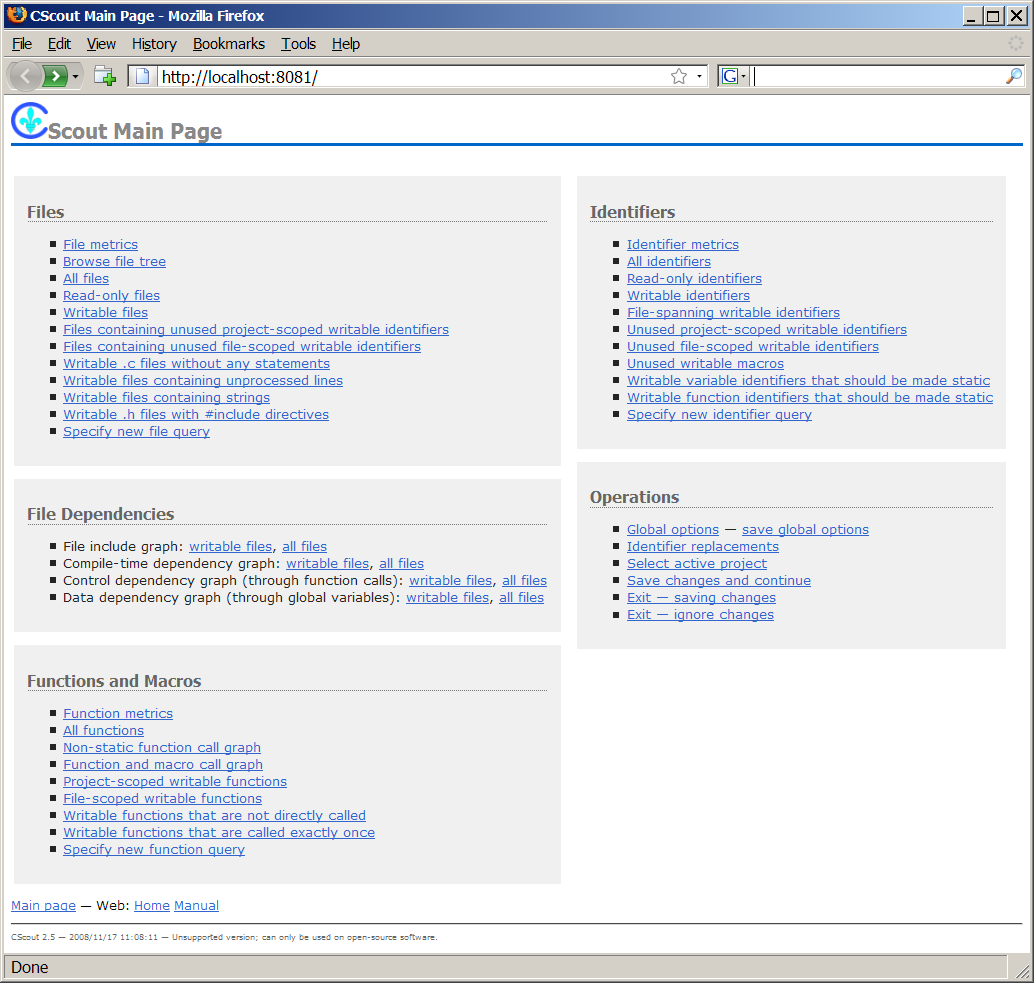
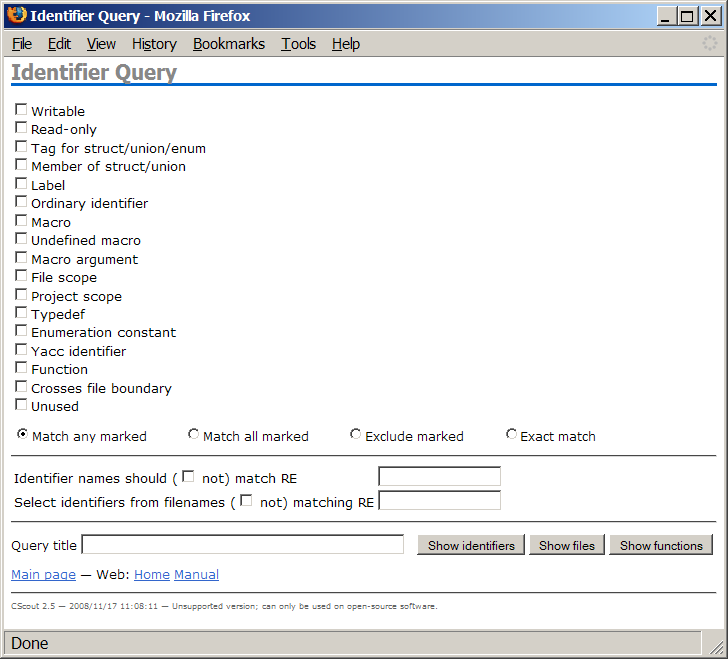
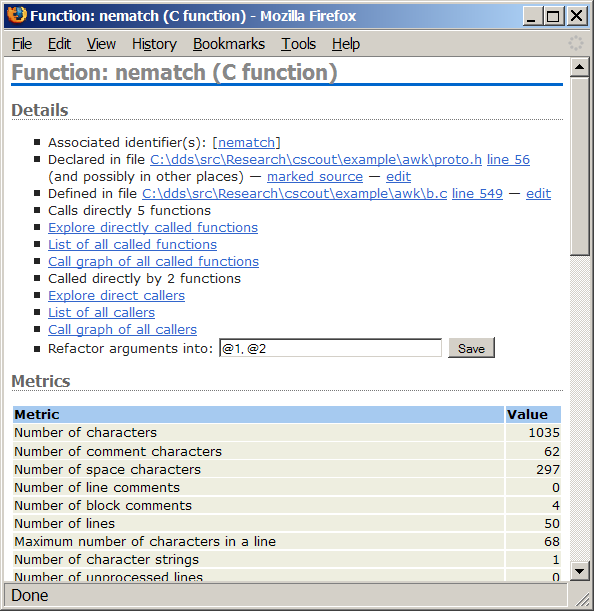
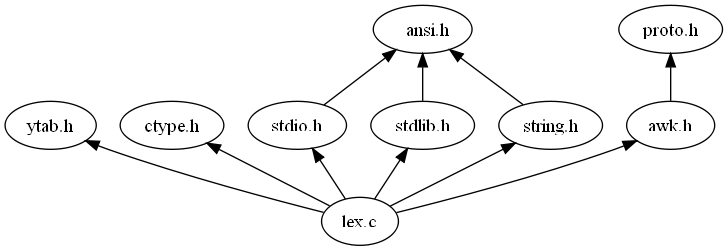
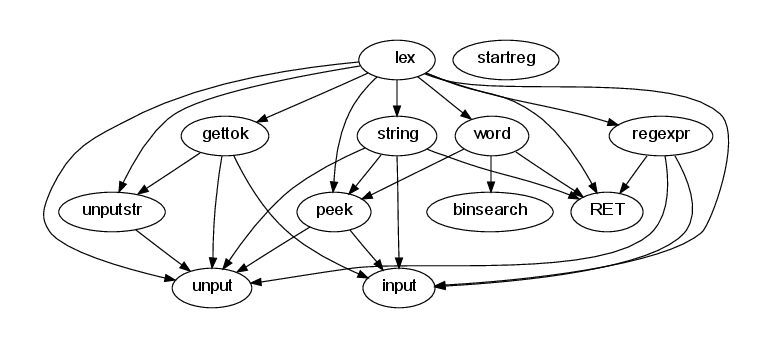
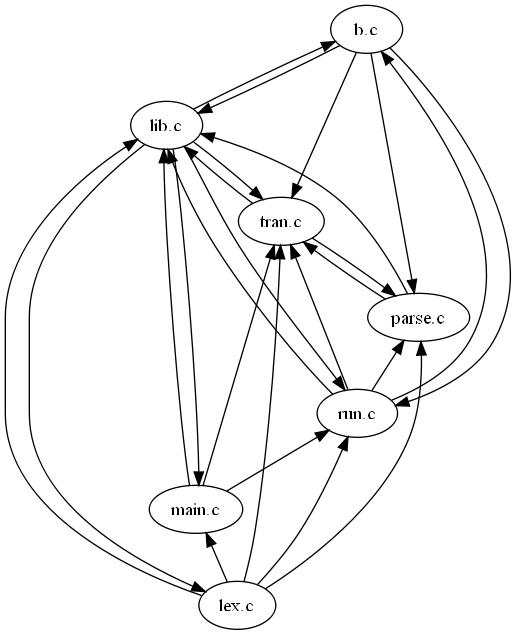
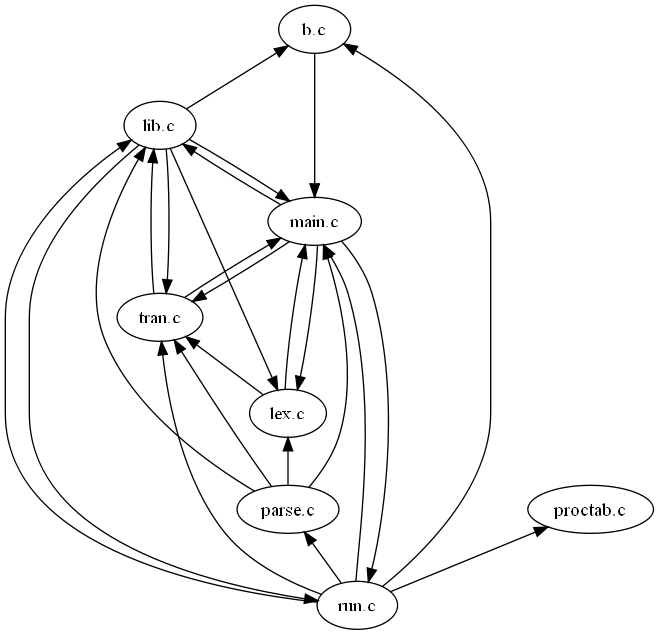
http://localhost:8081/fgraph.txt?gtype=Cto obtain the compile-time dependencies between a project's files. Furthermore, as all web pages that CScout generates are identified by a unique URL, programmers can easily mark important pages (such as a particular identifier that must be refactored, or the result of a specialized form-based query) using their web browser's bookmarking mechanism, or even email an interesting page's URL to a coworker. In fact, many links appearing on CScout's main web page are simply canned hyperlinks to the general queries we previously outlined.
+---------+-------+ | name | nfile | +---------+-------+ | NULL | 3292 | | u | 2560 | | printk | 1922 | | ... | ... |
| awk | Apache | Free BSD | Linux | Solaris | WRK | Postgre SQL | GDB | |
| httpd | kernel | kernel | kernel | |||||
| Overview | ||||||||
| Configurations | 1 | 1 | 3 | 1 | 3 | 2 | 1 | 1 |
| Modules (linkage units) | 1 | 3 | 1,224 | 1,563 | 561 | 3 | 92 | 4 |
| Files | 14 | 96 | 4,479 | 8,372 | 3,851 | 653 | 426 | 564 |
| Lines (thousands) | 6.6 | 59.9 | 2,599 | 4,150 | 3,000 | 829 | 578 | 363 |
| Identifiers (thousands) | 10.5 | 52.6 | 1,110 | 1,411 | 571 | 127 | 32 | 60 |
| Defined functions | 170 | 937 | 38,371 | 86,245 | 39,966 | 4,820 | 1,929 | 7,084 |
| Defined macros | 185 | 1,129 | 727,410 | 703,940 | 136,953 | 31,908 | 4,272 | 6,060 |
| Preprocessor directives | 376 | 6,641 | 415,710 | 262,004 | 173,570 | 35,246 | 13,236 | 20,101 |
| C statements (thousands) | 4.3 | 17.7 | 948 | 1,772 | 1,042 | 192 | 70 | 129 |
| Refactoring opportunities | ||||||||
| Unused file-scoped identifiers | 20 | 15 | 8,853 | 18,175 | 4,349 | 3,893 | 2,149 | 2,275 |
| Unused project-scoped identifiers | 8 | 8 | 1,403 | 1,767 | 4,459 | 2,628 | 2,537 | 939 |
| Unused macros | 4 | 412 | 649,825 | 602,723 | 75,433 | 25,948 | 1,763 | 2,542 |
| Variables that could be made static | 47 | 4 | 1,185 | 470 | 3,460 | 1,188 | 29 | 148 |
| Functions that could be made static | 10 | 4 | 1,971 | 1,996 | 5,152 | 3,294 | 133 | 69 |
| Performance | ||||||||
| CPU time | 0.81" | 35" | 3h 43'40" | 7h 26'35" | 1h 18'54" | 58'53" | 3'55" | 11'13" |
| Lines / s | 8,148 | 1,711 | 194 | 155 | 634 | 235 | 2,460 | 539 |
| Required memory ( MB) | 21 | 71 | 3,707 | 4,807 | 1,827 | 582 | 463 | 376 |
| Bytes / line | 3,336 | 1,243 | 1,496 | 1,215 | 639 | 736 | 840 | 1,086 |
| Item | Description |
| Computer | Custom-made 4U rack-mounted server |
| CPU | 4 × Dual-Core Opteron |
| CPU clock speed | 2.4 GHz |
| L2 cache | 1024k B (per CPU) |
| RAM | 16 GB 400 MHz DDR2 SDRAM |
| System Disks | 2 × 36 GB, SATA II, 8 MB cache, 10k RPM, software RAID-1 (mirroring) |
| Storage Disks | 8 × 500 GB, SATA II, 16 MB cache, 7.2k RPM, hardware RAID-10 (4-stripped mirrors) |
| Database Disks | 4 × 300 GB, SATA II, 16 MB cache, 10k RPM, hardware RAID-10 (2-stripped mirrors) |
| RAID Controller | 3ware 9550sx, 12 SATA II ports, 226 MB cache |
| Operating system | Debian 5.0 stable running the 2.6.26-1-amd64 Linux kernel |