|
http://www.spinellis.gr/pubs/jrnl/2007-SPANDE-FIRE/html/KS07.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
Citation(s): 2 (selected). The document's metadata is available in BibTeX format. Find the publication on Google Scholar This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder. |
Athens University of Economics and Business
Department of Management Science and Technology
Patission Ave 74 GR-104 34
Athens, Greece
| Automaton Type | Space | Time | Common Implementations |
|---|---|---|---|
| NFA | O(r) | O(r ×n) | grep, awk, perl, j2sdk |
| DFA | O(2r) | O(n) | tcl, automaton, FIRE/J |
| Operator | Description | Example | TR-Unix | POSIX |
|---|---|---|---|---|
| c | character match | a | √ | √ |
| . | Any character match | a.*a | √ | √ |
| [] | Character group definition | [a-z] | √ | √ |
| [^] | Negated group definition | [^a-z] | √ | √ |
| c* | zero or more character match | a* | √ | √ |
| c+ | one or more character match | a+ | × | √ |
| c? | zero or one character match | a? | × | √ |
| ^ | start of line | ^aaab | √ | √ |
| $ | end of line | aaab$ | √ | √ |
| c{x,y} | x minimum to y maximum occurrences of character c | a{1,2} | √ | √ |
| r - c | character r or c match | a - b | × | √ |
| Regular Expression | Example |
|---|---|
| [1-9][0-9]* | 1, 2, 3, 4, ... |
| ([a-f]) | a, b, c, d, e or f |
| a+ | a, aa, aaa, aaaa, ... |
| (m - n - kn - r)ight | "might", "night","knight" and "right" |
| (([0-9]+)?) - (([0-9A-F]+)?) | 1, 1A, AA, BF, FF, ... |
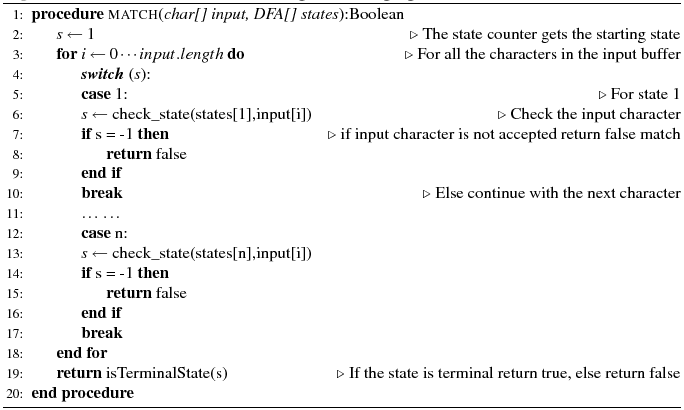 The algorithm receives as input a character sequence and the DFA states array, and returns a Boolean value indicating if a full match has been achieved. The generated code is a big loop with a switch - case statement. Starting from the initial state, all the characters in the input buffer are being checked against the transition rules of the DFA states. If a character does not satisfy the selected state, then the match fails and the procedure exits. When the input buffer runs out of character data, the last visited state is checked. If the state is terminal then the procedure returns true; otherwise it returns false. The structure of this algorithm is similar to the code generated by the lexical analyzer lex. In our implementation we have inlined all the methods, such as check_state and isTerminalState, in order to avoid the method call overhead [McC06,p601].
The algorithm receives as input a character sequence and the DFA states array, and returns a Boolean value indicating if a full match has been achieved. The generated code is a big loop with a switch - case statement. Starting from the initial state, all the characters in the input buffer are being checked against the transition rules of the DFA states. If a character does not satisfy the selected state, then the match fails and the procedure exits. When the input buffer runs out of character data, the last visited state is checked. If the state is terminal then the procedure returns true; otherwise it returns false. The structure of this algorithm is similar to the code generated by the lexical analyzer lex. In our implementation we have inlined all the methods, such as check_state and isTerminalState, in order to avoid the method call overhead [McC06,p601].
 If we define as n the number of states of the automaton, and m the size of the character sequence for the Algorithm 1, a total of n ×m of steps are needed to perform a full match, if the switch is naively compiled as a linear sequence of test and branch instructions. Consequently, the complexity of Algorithm 1 is O(n×m). For Algorithm 2, the required steps would be O(m), because each state jumps directly to the next or fails. We will see in section 6 that this technique provides significant performance gains.
If we define as n the number of states of the automaton, and m the size of the character sequence for the Algorithm 1, a total of n ×m of steps are needed to perform a full match, if the switch is naively compiled as a linear sequence of test and branch instructions. Consequently, the complexity of Algorithm 1 is O(n×m). For Algorithm 2, the required steps would be O(m), because each state jumps directly to the next or fails. We will see in section 6 that this technique provides significant performance gains.
|
|
| Operator | Occurrence | |
|---|---|---|
| . | 0 | .15 |
| + | 0 | .58 |
| * | 0 | .7 |
| ? | 1 | .39 |
| - | 3 | .85 |
| () | 5 | .08 |
| [] | 7 | .32 |
| Succeeded | Ratio | |
|---|---|---|
| J2SDK (Java) | 805 | 95 |
| Automaton (Java) | 685 | 81 |
| FIRE/J - Java (Java) | 665 | 78 |
| FIRE/J - bytecode (Java) | 665 | 78 |
| GNU (C) | 760 | 90 |
| Spencer (C) | 721 | 85 |
| Mono (C#) | 788 | 92 |
| Perl | 792 | 93 |
| 1st Quartile | Avg. | Median | 3rd Quartile | Max | |
|---|---|---|---|---|---|
| Size | 68 | 301 | 153 | 372 | 3394 |
| Length | 10 | 20 | 17 | 26 | 136 |
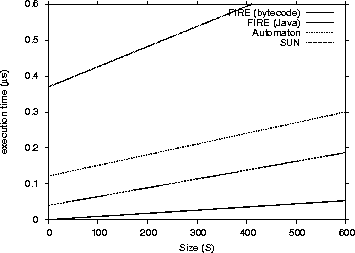
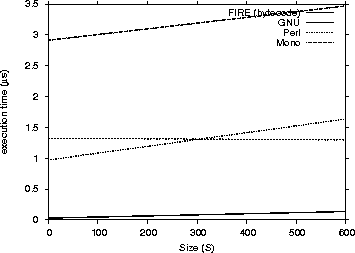
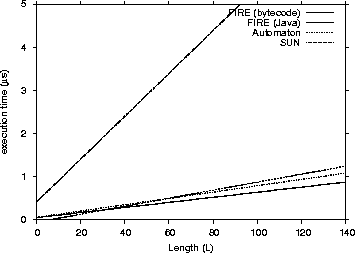
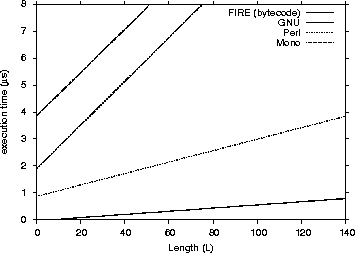
| Engine | 1st Quartile | avg | median | 3rd Quartile | max | |
|---|---|---|---|---|---|---|
| J2SDK (Java) | 132 | 357 | .92 | 227 | 371 | 69310 |
| Automaton (Java) | 115 | 200 | .78 | 177 | 253 | 1191 |
| FIRE/J - Java (Java) | 40 | 124 | .28 | 67 | 134 | 3039 |
| FIRE/J - bytecode (Java) | 33 | 75 | .45 | 50 | 72 | 4351 |
| GNU (C) | 120 | 1135 | .69 | 980 | 1630 | 18440 |
| Spencer (C) | 230 | 2497 | .87 | 680 | 2680 | 108700 |
| Mono (C#) | 434 | 928 | .59 | 667 | 1072 | 8004 |
| Perl | 90 | 128 | .08 | 107 | 144 | 672 |
(([01]?[0-9][0-9]?|2[0-4][0-9]|25[0-5])\\.){3}([01]?[0-9][0-9]?|2[0-4][0-9]|25[0-5])
The second regular expression involves a verifier for an Apache web server log entry:
([0-9]{1,3}\\.){3}[0-9]{1,3}[ \\-]+.[0-9]{1,2}/[a-zA-Z]{3}/[0-9]{4}:[0-9]{2}:[0-9]{2}
:[0-9]{2}[ ]\\+[0-9]{4}.[ ].(GET|POST)[ ][a-zA-Z/~0-9.%]+[ ]HTTP/[1-9]\\.[1-9]{1,2}.
[ ][0-9]+[ ][0-9]+[ ].-.[ ].[a-zA-Z0-9./]+[ ]\\(.+\\)[ ][a-zA-Z/0-9]+[ ][a-zA-Z/.0-9]+.
The data we used included were a 15-character IP address (255.255.255.255) and an Apache log entry of 193 characters length. Table VIII shows the results of the benchmark process. As we can see the FIRE/J engine is faster than all its competitors.
It is also interesting to note, that the FIRE/J-Java generator loses slightly from the automaton engine in the more complex regular expression. Our experiments showed that the FIRE/J-Java generator loses matching speed when the DFA has many states. In this case the generated class file is very big in terms of size, which causes cache misses that compromise the overall performance of the engine. The FIRE/J-bytecode generator will have eventually the same performance problem for more complex regular expressions.
| IPv4 | Apache Log | |||
|---|---|---|---|---|
| J2SDK (Java) | 3 | .5 | 33 | .8 |
| Automaton (Java) | 0 | .3 | 4 | .6 |
| FIRE/J - Java (Java) | 0 | .2 | 4 | .9 |
| FIRE/J - bytecode (Java) | 0 | .1 | 1 | .2 |
| GNU (C) | 9 | .2 | 67 | .4 |
| Spencer (C) | 118 | .4 | 7094 | .8 |
| Mono (C#) | 14 | .5 | 39 | .0 |
| Perl | 3 | .8 | 6 | .0 |
| Engine | Compile Time | Break-even point | |
|---|---|---|---|
| J2SDK (Java) | 62 | .0 | n/a |
| Automaton (Java) | 43,992 | .0 | 32,280 |
| FIRE/J - Java (Java) | 260,904 | .0 | 247,255 |
| FIRE/J - bytecode (Java) | 115,690 | .0 | 24,313 |
| GNU (C) | 160 | .4 | n/a |
| Spencer (C) | 62 | .0 | n/a |
| Mono (C#) | 5 | .3 | n/a |
| Perl | 0 | .9 | 0 |